Reprinted in COMPUTER NETWORKS: A Tutorial ed. Marshal Abrams & Ira W. Cotton IEE Catalog Number EHO213-9 1984. Originally published in IEEE Transactions on Communications, Volume COM. 29, Number 4, April 1981, pages 413-426. Copyright © 1981 by The Institute of Electrical and Electronics Engineers, Inc.
Manuscript received June 16, 1980; revised November 26, 1980. The author is with the Centre National d'Etudes des Te1ecommuniclions (CNET), 92131 Issy les Moulineaux, France.
110213-9/84/0000/0273$01.00 @ 1981 IEEE
Methods, Tools, and Observations on Flow Control in Packet-Switched Data Networks
LOUIS POUZIN
(Invited Paper)
Abstract-Flow control covers several concepts. In an end-to-end connection, it intends to adapt sender's output to receiver's capabilities. In a shared resources communication network, it attempts to prevent congestion by restricting traffic flows.
Flow control mechanisms are built with a small number of basic throttling tools. However, they are always tied into a resource management problem, which depends on a large variety of environmental parameters. Techniques used in end-to-end connections are summarized. Congestion control in store-and-forward packet-switching networks is covered extensively, and techniques used or proposed are discussed. Memoryless networks such as broadcast networks are shown to be simpler systems in the area of flow control.
In conclusion, arguments are made for a service oriented approach, which would optimize resource usage through differentiated service characteristics.
INTRODUCTION
WATCHING car traffic from a tower in a busy city is a fascinating pastime. Little snags, such as a car slowing down, or changing lane, may escalate gradually into a heavy snarl, long after the initial cause has disappeared. Jammed spots move upstream at a certain speed, as ripples on still water. Traffic clogs some thoroughfares while bypass streets remain deserted.
Similar problems arise in communication networks in which bandwidth is the equivalent of street width, buffer is an approximation of the space occupied by a car on the ground, and supervision packets are police cruisers. The high perched observer of car traffic may be helpless, but at least he can see how cars move or pile. If he were a radio speaker, he could perhaps warn drivers. Packets are like moles, but faster. No one sees them, and it is hard to spy out what is happening when network traffic becomes unstable.
Although problems of traffic control have been discussed even before packet networks became operational, they are still not well understood. Recipes have been proposed and to some extent validated by simulation and experience, but why they work, and within what limits, is largely a matter for speculation.
This paper attempts to cover the subject of flow control in packet networks from an engineering point of view.
Section I is mostly introductory material and definitions.
Section II is basically tutorial and presents the tool kit available to network designers.
Section III is the core of the paper. It explains and discusses major typical schemes explored for end-to-end control over individual data streams, and congestion control in packet networks. Schemes used in store-and-forward packet networks may apply to independent packets (datagrams), or packet streams (virtual circuits). Problems related to routing and topology are also mentioned. The case of memoryless networks (e.g., rings) is shown to be simpler than the control of store-and-forward networks.
Section IV suggests a practical approach to flow control as a global resource management scheme. By defining nonconflicting classes of services, network resources could be apportioned in order to meet the characteristics of a service policy.
Research on traffic control in packet networks is still needed, although it may not mature in time to be applied. Indeed, new technologies are likely to obsolete existing designs intended to optimize the use of low bandwidth fixed circuits. High rate broadcast media and fast digital will eventually place flow control in a totally different context.
I. CONCEPTS
Flow control (FC) is often assumed to be primarily a set of protective functions such as
no traffic loss that could occur when a receiver is flooded
- avoid interference between users, and
- protect the communication network against clogging.
These are three unrelated objectives, and negative ones at that, as opposed to error control, whose well defined goal is to catch all errors of a certain type, there is no clearcut objective for FC. If only the previous ones had to be met, it would be a relatively simple matter, using, possibly, a specific for each one. But it might also turn out that the end result would be disastrous in terms of throughput and resource utilization. Actually, there are other objectives which least as important, if not more, than the ones mentioned
- minimize response time in conversational traffic,
- maximize useful throughput,
- minimize transmission cost,
- keep the receiver busy at all times, and
- minimize overhead.
These latter objectives are more related to a good economical between benefits and drawbacks of FC mechanisms. The diversity of objectives suggests that there cannot possibly exist a single good FC scheme. Depending on the environment, some objectives will be considered essential, while others will be immaterial, or just secondary. But it would be impractical for and suppliers to support a multitude of application implementations. Therefore, a practical objective is to devise parameterizable FC schemes lending themselves to particular tunings and strategies.
This is an indication that in a real environment an FC strategy is a delicate balance between conflicting objectives. It calls upon a battery of mechanisms, each one specialized in a certain variety of resource management and simple functions.
Finally, due to the complex multivariate environment of FC implementations, results cannot be predicted with guaranteed accuracy. Measurement tools are needed to check results and point out means towards desirable improvements.
B. Definitions
Flow control is the set of mechanisms whereby a flow of data can be maintained within limits compatible with the amount of available resources.
Resources required to carry a flow of data can be categorized in two classes:
- basic: buffers, transmission bandwidth, and processor time; and
- incidental: name space, table entries, logical channels, etc.
Basic resources are always required in a store-and-forward (S-F) computer based communication system. Incidental resources are usually required, but they are primarily dependent an the implementation.
End-to-End (E-E) flow control is the set of mechanisms whereby an endpoint receiver maintains the sender traffic within limits compatible with the amount of resources available at the receiver end.
By definition, E-E flow control is not concerned with problems of resource availability that may arise within intermediate subsystems interposed between sender and receiver. Typically, intermediate subsystems are shared between a number of sender-receiver pairs (Fig. 1), e.g., a telephone line, or a packet network.
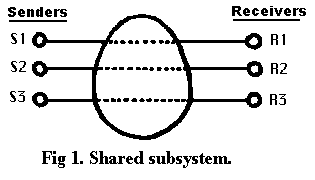
Congestion control is the set of mechanisms whereby an intermediate subsystem maintains input traffic within limits compatible with the amount of resources available to the subsystem.
It results from the above definition that congestion control may require mechanisms capable of throttling some sources in the event that the subsystem cannot carryall the offered traffic.
II. IMPLEMENTATION TOOLS
A. Basic Throttling Tools
FC schemes are usually a combination of several interacting functions working at one or several layers in a system architecture. In practice, any FC implementation involves a limited number of throttling tools, which are summarized below.
Stop and Go: A source is controlled by signals of a binary nature. Either it can send traffic without limit, or it is barred from transmitting. This technique is used in most data link control procedures, such as BSC or HDLC. It is also the principle of handshaking signals in electrical interfaces. A stop or go signal takes effect immediately, or at the earliest opportunity after the transmission currently in progress.
The receiver has to take into account the transit delay necessary to carry stop/go signals to the sender. On terrestrial links, this delay is negligible with regard to the transmission time of a message of tens of thousands of bits. Satellite links or S-F systems may introduce delays equivalent to. the transmission time of several consecutive messages. Thus, when a receiver sends a stop signal, a certain amount of traffic may continue to arrive for a while. This amount of traffic is composed of outstanding messages at the time the stop signal , carried to the sender. One can easily understand that long and variable transit delays make this tool completely ineffectual, because the amount of outstanding traffic may vary within large limits.
Credit: The sender cannot transmit unless it has received from the receiver an indication about the amount of traffic that can be accepted. This quantifying scheme protects completely the receiver from an excess of arrivals.
The amount of acceptable traffic may be indicated in terms of bits, characters, messages, sequence of messages, message numbers, etc. An extreme case is an infinite credit, which puts the sender in a freewheeling mode.
Polling may be viewed as a particular case of a credit scheme, since a poll message conveys the right to send just one sequence of messages.
Error control schemes are often used as a rudimental form of credit FC. Indeed, acknowledgments usually carry two meanings: good reception and a credit to send one or more additional messages. This does not mean that error and flow control are the same thing. It only means that in certain implementations, error and flow control signals may be condensed in the same messages.
A credit scheme requires certain safeguards, e.g., should a credit be given forever, and possibly not used? What if a credit gets lost or duplicated? Discussion of these issues is deferred to a later part of this paper.
Rate: The sender transmits traffic at a predetermined rate, which may have been evaluated with regard to resources required. Rates may be adjusted dynamically when the resource supply is changing.
A typical application of that scheme is the feeding of output peripherals, working at a well-known speed. Devices such as character terminals are usually unable to control senders. The only way they can operate properly is to be fed characters at their own pace.
Time slot allocation schemes are a variety of rate controlling mechanisms. They have been used extensively for CPU sharing and transmission line servicing by a communication controller. Loop networks, and special satellite broadcasts have stirred up research in slotting methods, which mushroom by the dozens.
Delay: In any organization, increased delay is a way of throttling, if not discouraging, user demands. Indeed, the useful lifetime of information is limited. When transit delays increase, some traffic gives up, as service degradation becomes intolerable. This is typical of on-line applications, where tolerance is related to human behavior. With automated users, tolerance is usually determined by the setting of a timer, or by a threshold in the number of unsuccessful attempts. An extreme case of increased delay is discarded traffic, which is tantamount to infinite delay. In other cases, senders do not give up, they just keep sending. This may have adverse effects depending on system implementation.
A conventional message switching system equipped with secondary storage may be considered as an infinite sink, and can introduce long transit delays. In this case, increased delays have no immediate effect, as senders are usually not aware of transit delays. Thus, other mechanisms are necessary to prevent input traffic from using up all available storage when some destination gets blocked.
More often, senders and receivers are coupled via an E-E protocol requiring some form of receiver acknowledgment, which limits the amount of outstanding traffic. In this case, increased delay has an immediate effect in throttling senders, because they have to wait for receiver acknowledgment before they can proceed.
Delay may result from the saturation of a shared resource (processor, line, buffer pool, virtual call table, etc.) or from a deliberate decision in traffic management, such as low priorities or diversion onto longer routes.
Using delay as a throttling tool is a tricky game. Indeed, outstanding traffic must be stored, and somehow managed for a longer time. Thus, more resources are required to carry the same amount of traffic while degrading the service. The system may enter an unstable domain where more and more resources are consumed with less and less delivered traffic. A good analogy is a car traffic jam in busy cities.
Class: Traffic is offered with a class indicator. When enough resources are available, all offered traffic is accepted and carried. Otherwise, some classes are restricted depending on criteria which appear to strike an acceptable balance between conflicting user demands. Restriction may be in the form of longer delay, limited input rate or credit, limited number of destinations, or a class may even be denied service entirely.
In other words, a class scheme is just a level of traffic segregation, leading to the application of some specific throttling policy, which may be selected dynamically. In a sense, it is a preliminary level of service selection.
B. Incidental Throttling Tools
As the qualifier incidental implies, there may be an almost unlimited number of mechanisms which may induce throttling as a side effect. Here follow a few examples which may be encountered in some existing systems.
Name Space: In some systems, names must be obtained to designate sender and receiver before they can exchange useful traffic. If names are not sharable, and if they are in limited supply, traffic will necessarily be kept under some limit.
Another example of traffic throttling due to a restricted name space is a cyclic message numbering scheme. Since message numbers are reused, and are usually essential for error control, traffic must be stopped when unacknowledged messages take up all available names [5].
Table Entries: Any S-F communication system uses internal tables to keep track of the resources being managed. For example, in some systems there may be a "virtual circuits" table in a number of network nodes. Since the number of ongoing calls is not necessarily predictable, there may be traffic limitations due to a lack of available table space.
Overhead and Delays: Protocols and system interfaces are a customary cause of traffic limitation, when they introduce queueing delays, response times, or redundant messages.
C. Flow Control Constituents
As can be inferred from the description of basic throttling tools, FC is a mixture of two distinct constituents, which must be clearly distinguished, if one is to conduct a sensible analysis.
The first constituent is a FC protocol, Le., a set of conventions followed by both sender and receiver to exchange control information pertaining to the flow of data. For example, go signals, credits, rates, priorities, etc.
The second constituent is a resource management scheme, i.e., a mechanism keeping track of all allocatable resources, and granting allocations to a number of resource consuming processes. When resource management is distributed, its various components need to exchange control information. Rules for exchanging this control information are a FC protocol. example, a credit scheme such as used in the CYCLADES E-E protocol [47] only specifies the format and the meaning of credit control fields in message headers. How the receiver determines the proper credit value, and what resources are booked is a local management problem, which the receiver may handle in a number of ways. A possible solution to that problem could be
- send a credit for a certain number of messages; this number may be constant, to keep the traffic even, or it may vary on criteria such as system load or network estimated traffic;
- allocate one message buffer for the first incoming message;
- as soon as a message starts arriving, get another buffer from the free pool;
- if there is no buffer available, send a stop signal to the local data link procedure; and
- as soon as a buffer is obtained, unblock the local data link procedure.
This scheme is obviously dependent on the local environment which is assumed to manage a buffer pool normally not depleted. If the receiver were allocated permanently a fixed of buffers, it could send a credit for the exact number of free ones.
The sender has no knowledge of the specific scheme used by the receiver and it does not care, as long as it receives credits. On the other hand, the sender has another resource management problem if it is sending traffic to several correspondents. It must share one (or more) physical transmission lines among a number of messages ready to go.
It can be derived easily from intuition, and this is confirmed by simulation [25] , that traffic throughput is primarily dpendent on resource management schemes, and occasionally FC protocols. It would be totally naive to claim that a FC protocol alone gives any guarantee for a satisfactory traffic throughput. However, an inappropriate FC protocol can certainly aggravate the problem.
D. Protocol Booby Traps
It would be unrealistic to assume that errors would never occur in a communication system. Thus, it is worth looking at the implications of various classes of errors in a FC protocol.
Transmission Errors: Corrupted messages are supposed to be discarded as a result of checksum mismatch. There remain the cases of lost or duplicated messages.
If a stop signal is lost, oncoming traffic may exceed the capacity of the receiver. But, if a go signal is lost, the sender remains silent. Therefore, such signals should be protected against loss. They may be embedded within messages subjected to error control, or they may be acknowledged individually. In order to prevent confusion between acknowledgments, it is necessary to use a numbering scheme, or to rule out more than one outstanding signal.
Duplication of stop/go signals would do no harm if duplicates were delivered consecutively. But there may be situations, like the following, as seen by a receiver: stop go duplicate-stop.
Even if every signal is acknowledged, the result is not what the sender wanted. When duplicates may be delivered out of sequence, it is necessary to introduce echoing or a numbering scheme, in order to discriminate valid signals.
Similar considerations would apply to a rate control based on the exchange of rate indicators. Stop and go are just two extreme values of a rate setting protocol.
Credits pose a slightly different problem, because this scheme implies that both sender and receiver keep in agreement on the amount of allocated messages. In case of discrepancy, there may be an excess of arriving messages, or the sender gets blocked while the receiver is waiting.
Acknowledging every credit allocation is not a common scheme as it introduces additional overhead. There could be a periodic synchronization, but that only limits the duration of a drift. In practice, schemes based on the correct exchange of credit values, without loss, are vulnerable, and no longer utilized.
In order to prevent drifting, a self-correcting scheme was introduced initially in CYCLADES [47], and appears to be generally adopted in more recent designs. It assumes an error control scheme based on message numbering. Credit is expressed as the highest message number the receiver can accept. A condensed form is an increment to the last acknowledged message number. The span of message numbers between the last acknowledged one and the highest credit is called the "window." This is what the receiver transmits to the sender (Fig. 2).
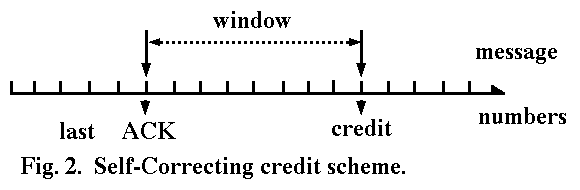
It can be understood easily that every credit indication supersedes the previous one, since it points to an absolute message number. Synchronization is established for each credit given. Thus, duplication is harmless; loss is automatically recovered by the next credit carrying message.
Out of Sequence: There may be messages arriving out off sequence when using a communication system based on "datagrams," i.e., independent packets [31]. This point has alread1y been brought up in the previous discussion about stop/go signals. There are obvious cases where out of sequence FC signals could lead to blocking or overflow. Then, it is appropriate to number signals or credit indicators.
Actually, the numbering is obtained as a byproduct of embedding FC information within message headers on the reverse direction. On the other hand, if FC information is sent as separate messages, it may use regular message numbers. Sending credits as (ACK + window) provides also for an easy way of reordering out of sequence messages, since acknowledgements sent are increasing numbers (modulo the cycle).
Deadlocks: It has been mentioned previously that the loss or nonsequenced delivery of FC information could lead to silencing the sender. As explained just earlier, this should not occur in a well designed FC protocol. However, errors do occur in protocol design, and also in implementation. Therefore, it is commendable to rely on last resort safeguards, which include: periodic status exchange in the absence of normal traffic, ability for the sender to request credit, and ability to send short messages (interrupts) even in the lack of credit. These handy tools are most helpful to recover from abnormal states.
Overflow: Even with a flawless FC protocol, there may occur situations involving risks of traffic overflow. For example, after having sent a credit, the receiver gets into trouble and wants to stop traffic. It may be too late to prevent the sender from using that credit. On the other hand, local resource management may rely on statistics in allocating more credit than the amount of available resources. This is common in handling stochastic traffic.
There is still some prejudice against overflow, as if it were an absolute evil. A better look is from an economic point of view. Taking no chance of overflow requires more resources than taking some chances. For a specific environment, it would be possible to study the relation between resource cost and probability of traffic loss. On the other hand, traffic loss is not a serious problem with error recovery mechanisms. It translates into some figures of retransmission overhead, cost, and delay. As a whole, there must be an acceptable balance taking into account all costs and resources.
Some minimal rate of overflow may save a substantial amount of buffers. But it is clear that frequent overflow would lead to a loss of bandwidth, not only due to retransmission, but also to idle periods associated with error recovery. When throughput is at a premium, overflow probability should be kept very low.
III. FLOW CONTROL SCHEMES
A. Distributed Resource Management
For the sake of analysis and understanding, FC problems have been sorted out into logically independent domains: 1) protocol tools, 2) local resource management, and 3) pitfalls. We have also discussed some aspects of cost effectiveness, which point out interferences between remote components.
Although sender and receiver resources can be managed independently, overall efficiency depends on the proper balance between local strategies.
The introduction of a shared subsystem brings up additional problems. For example, a sender/receiver pair may attempt to keep a smooth steady data flow and be completely defeated if an intermediate packet network plays havoc with frequent packet loss, and unpredictable transit delays. Thus it would seem that FC strategies require a global analysis and tuning, taking into account all resources involved. This is not very practical, as it is too complex, and some components are provided as black boxes by independent suppliers. Furthermore, a sound system design approach requires independent layers.
Instead of getting entangled into low level details, intermediate components or layers may be thought of as simplified models defined by a set of quantitative characteristics: transit delay and distribution, bandwidth, error rate, facilities offered, etc. Components may be placed into two categories: shared and endpoint.
Two endpoint components deal with each other through an E-E protocol. They also interact with an adjacent subsystem through a local interface (Fig. 3).
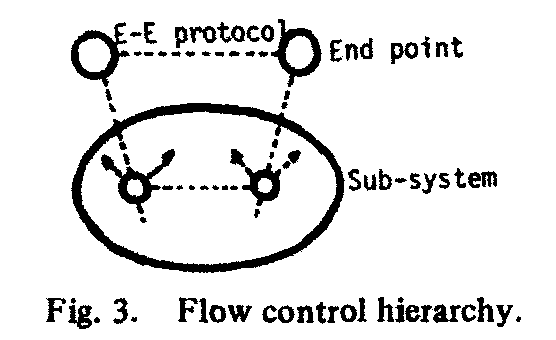
This model presents the advantage of decoupling resource management problems at each level. It also ensures protocol independence, within the limits of the assumptions made on the characteristics of the subsystem.
Subsystems are normally shared by a number of endpoint components, and attempt to meet for each one the service characteristics as advertised. They may split up systems and end point components at their own level. But this is not visible from the outer layer.
When subsystems fail in providing a service in accordance with advertised characteristics, they are in pathological conditions. E-E protocols should be designed to be efficient in normal conditions. They should also resist pathological ones, with a possible loss of efficiency.
B. End-to-End Flow Control Protocol (E-E FC)
The FC protocol is not a fundamental issue, as it does not fall in some of the traps reported previously. Here are some typical requirements:
a) specified throughput determined by the slower endpoint, for steady data flows;
b) maximum throughput when the subsystem limits traffic
c) minimum delay for bursty traffic; and
d) guaranteed delay and throughput for real-time traffic.
In case a), E-E FC has an effect only when the receiver is the bottleneck, e.g., an output peripheral. A specified throughput is obtained when the receiver has never to wait for traffic. In other words, there are always one or several messages queueing for the receiver. Since the sender must keep copies of transmitted messages until it has got acknowledgment, there is no advantage in building long queues in front of the receiver; the smaller, the better. Ideally, it would be sufficient that a new message arrives just at the time the receiver would go idle. In the absence of variations in transit delay, this would require perfect synchronization between sender and receiver. This is impractical; transit delays do vary. Therefore, it is necessary to provide for some queueing on the receiver side, in order to damp out the variations in transit delay and sender output rate. Should variations follow a nice mathematical pattern, the queue size could be determined by analysis. Otherwise, experimental tuning is easy.
A credit scheme is quite appropriate to that sort of FC requirement, as it allows periodic sender wake up for a certain amount of traffic. In addition, an indication of the desirable rate may help the sender schedule its output process.
In case b), the game is to pump in traffic up to the subsystem acceptance limit. E-E FC has no effect for dealing pathological conditions arising within the subsystem, which needs mechanisms to protect itself and throttle senders. This is dealt with in a later section on congestion control.
In case c), average throughput may be highly variable, but normally below acceptable thresholds. The emphasis is on low delay. E-E FC is only effective to curb long bursts, which would appear as case a). In normal conditions, low delay depends on the characteristics of the subsystem.
Case d) may involve bursty and steady traffic. It appears combination of the requirements of cases a) and b).
Taken to the letter, a guarantee of service characteristics implies a guarantee of available resources. That is, the problem primarily a matter of resource management. However, some resource management policies may impact the FC protocol, in the sense that they require explicit declarations of the amount of resources to be secured. This may take the form of request messages (e.g., open/close virtual circuits), or various parameters settings (e.g., throughput class in X.25).
In conclusion, E-E FC is an appropriate and little constraining tool for cases a), b), and c) as long as the subsystem does introduce any substantial limitation. Case d) is more demanding, and requires careful resource management, both in endpoints and communication subsystems.
Endpoint Resource Management: As we just discussed, a credit scheme is appropriate for E-E FC, although it does not compensate for the constraints deriving from the communication subsystems. In addition, resource management at each endpoint may raise specific problems. Typically, traffic exchanged between sender and receiver may be limited primarily by communication bandwidth or computing resources (processor, memory, I/O channel). We shall examine now the implications of each situation.
In long haul communication networks, bandwidth is usually so limited that calls for memory buffers or processor cycles be satisfied in much less time than it takes to send/receive a message. Credits given to senders can be honoured without necessarily tying up more than a small amount of buffers, typically one for each message being reassembled. That is, receivers can "lie" in promising buffers which may not be available at the time credits are sent. Nevertheless, by the time buffers are needed, the receiver can manage to find some. A common strategy is to share a buffer pool among many receivers, or alternatively, to page out inactive buffers.
On the other hand, short haul communications systems, i.e., local networks, can provide so much bandwidth that usual limitations are processor cycles or buffer space. In that case, long bursts or steady high speed traffic may exceed receiver capacity. If that is the case, a credit scheme is insufficient. Lying about buffer space would be defeated, because the receiver could not find space fast enough. Tying up as many buffers as credits given would result in too bulky reservations. A solution is to introduce requests for credits in the E-E FC protocol [29]. Credits are no longer given a priori; they must be requested by senders, when needed. They are granted depending on resource availability, and they may be withdrawn if not used within a certain delay. Of course, there is an overhead in bandwidth and delay for placing credit requests, but this is not important in the context of high speed local networks.
Credit Management: The way credits are given may have a strong influence on flow stability, throughput, and overhead [1], [20], [21], [22], [25], [40], [43], [45]. When transit delays are substantial, it is clear that credits must be sent early enough if one does not want the sender to come to a halt. There are pros and cons in handling credits, depending on how system components work. Let us examine various issues.
- In order to keep maximum throughput, there is no need to give more than a certain amount of credits. This result from the pipeline effect of the communication network. For a certain data rate, it is possible to determine the average and the maximum number of messages in transit. If credits travel at the same speed as data messages, they need not exceed twice the amount of messages in transit.
- Stopping the sender may induce overhead in context switching, paging, scheduling, etc. in the sender system. Also, the communication network may release buffers or slots, if their reservation is contingent on traffic stability. Reinstalling resources costs delay and overhead.
- When the sender nominal data rate is too high for the receiver, frequent halts or short messages may induce excessive overhead. It may be more efficient to wake up the sender for long shots, and let the communication network damp out message bursts. Then, credits should approach the amount of data the communication network can absorb before fighting back.
- If credits take separate messages, and if they are charged for full ones, it pays to minimize their number by granting larger credits.
- It may be necessary to restrict credits in order to optimize error recovery. This is more likely to happen with long transit delays, lossy networks, and sequential retransmission.
- When protocol conversions are performed in intermediate components (e.g., a gateway interconnecting two networks), it is not always possible to map precisely FC protocols, and overflow could occur if larger credits were given [2]. Very often, the limit is determined after a few accidents have happened.
As one may observe, distributed resource management raises numerous issues which have no intrinsic relationship with an FC protocol. They illustrate subtle interferences between system layers, and the vanity of optimization out of context.
C. Congestion Control
In a shared subsystem, FC is less simple than in E-E flows, as it has to deal with apportioning resources to a number of conflicting and diversified demands.
There are two classes of communication systems carrying packets: store-and-forward (S-F) networks, and memoryless networks, in which packets are never stored (ALOHA, DCS, ETHERNET). If we define congestion as the state where more offered traffic results in less carried traffic, then both networks classes are subjected to congestion. However, technical issues are quite distinct, and it is appropriate to discuss them separately.
1) S-F networks: As soon as packet networks were conceived, it was recognized that too many packets in transit could deteriorate network performance [6].
Packets in transit use resources: buffers, bandwidth, and processor time. When traffic increases, queues build up and delays increase [38]. There is no simple way to determine, instantaneously, global network throughput, and nascent congestion. Furthermore, in a physically distributed system there may appear local congestion areas which do not necessarily affect substantially global behavior. Thus, practical schemes rely upon the local observation of some critical resource usage, which is presumed to be a sensitive indicator of network load [11], [24]. Somehow, all known studies but one picked buffers as the only critical resource. One experimental network, CIGALE [30] , investigated mechanisms based on bandwidth, and no one seems to have considered processors as a potential bottleneck.
Packets cannot be forwarded when the next node has no buffer available. This in turn increases buffer occupancy by packets waiting to be transmitted, and depletes buffers available for arriving packets. The first effect is slow moving packets and increased transit delays. More drastic degradation occurs when deadlocks appear. The most common form is mutual lockup between two neighbor nodes, which want to send packets to each other, but lack the necessary buffers to receive them. There are other more complex forms of deadlocks [17].
It was speculated that congestion would be avoided if there always remained enough free buffers. A solution would be infinite storage, such as disks, tapes, etc. However, existing packet networks have been designed to deliver packets within a finite delay, which is usually too short for using buffers on secondary storage. Thus, providing enough free buffers is not sufficient. Packets may accumulate in the network because destinations are too slow to accept them, or shut off entirely. Therefore, a complementary objective is to prevent offered traffic from flooding the network when it exceeds delivered traffic.
This problem was submitted to mathematical analysis, simulation, experiments, and a. number of techniques may now be identified. They are represented on the diagram in Fig. 4.
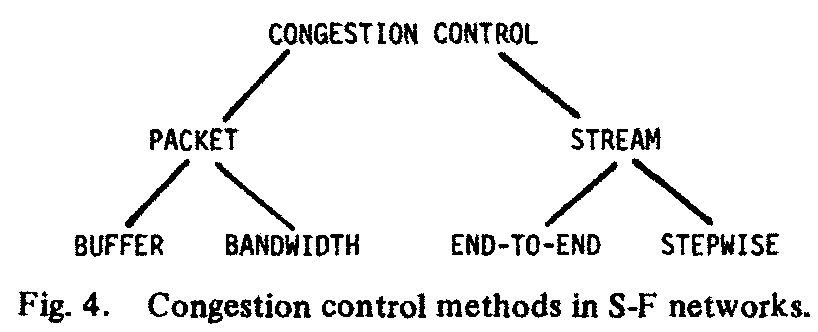
Congestion control schemes diverge mainly on the manner input traffic throttling is related to delivered traffic. Methods that require identifying source-destination pairs are called here stream-wise, and are discussed later. We shall discuss presently those methods which derive input traffic throttling solely from the observation of unrelated individual packet traffic. We categorize such methods as packet-wise.
a) Packet-wise: Packets are taken as independent individual entities. This technique for switching packets has been called datagram service [31]. No attempt is made to relate packets to prior or subsequent traffic. As indicated previously, most studies have concentrated on buffer management.
i) Buffer: Several schemes have been studied and appear to yield satisfactory performance. In the following we briefly describe three of them, which have been called isarithmic, input buffer limit, and buffer class.
Isarithmic: Historically, the first scheme devised has called isarithmic [6]. Its idea was to keep the total number of packets in transit below a certain threshold, which could be considered as the maximum network load. Initially, the network is given a number of permits, which are kept on the move. When a packet is presented to a network node, it has to acquire a permit, which is released when the packet is delivered by the destination node.
This simple method was never implemented, but simulation showed that it was very effective in keeping rather stable, and excess traffic out of the network [33]. However, assumptions made were that traffic increased at every input node. Although the network as a whole not get congested, there could appear locally congested areas, specially with unbalanced traffic [45]. Furthermore, the implementation of this scheme is difficult, because it is very sensitive to the total number of circulating permits. Node failures and topology changes are potential sources of permit instability.
Input buffer limit (IBL): While simulating the isarithmic scheme, it appeared that simple priority rules for allocating buffers could be as efficient in preventing congestion, while improving performance slightly [33], [35]. Each node is allowed to store up to a certain maximum number of packets. Packets reaching their destination node are given highest priority. Then, packets in transit have second priority, while packets entering the network have lowest priority and cannot take more than a certain maximum number of buffers. This scheme may be implemented easily, and it is much less vulnerable to node failures than the isarithmic scheme. Its effectiveness in preventing congestion is also supported by analysis [23].
Buffer class (BC): The initial idea was that congestion resulting from deadlocks could be avoided if deadlocks were avoided [36]. To that effect, buffers are divided up in as many classes as there are hops along the longest route through the network. When hopping to the next node, a packet can only be received into a buffer from the class corresponding to the number of hops already made. There cannot be deadlocks, since this scheme applies the well-known rule of allocating resources in a predefined order. However, buffer distribution is a problem. If fixed amounts of buffers were allocated to every class, they would be mostly underutilized, since it is not possible to predict in heavily loaded conditions how many buffers of each class are necessary in each node. On the other hand, with dynamic allocation out of a buffer pool, nodes may fill up almost entirely with entering packets. Since there is always a minimum of one buffer in the next class in sequence, packets will eventually move, though at a much slower pace than in the conditions of highest throughput.
In order to prevent congestion, the amount of buffers allocated to input packets must be restricted to an optimal figure [34]. At this stage, the BC scheme becomes essentially equivalent to the IBL scheme, and it proves to be as effective ill simulation [13]. A real implementation would be more complex in the face of dynamic routing and topology changes, as the maximum number of hops would no longer be predictable precisely.
Except for the isarithmic scheme, congestion control methods applying a buffer management policy exert some selectivity in handling traffic. Roughly speaking, priority is increasing with the distance from the source because more resources have been invested. This policy is geared towards optimizing resource usage, but it does little to share resources fairly among competing users.
ii) Bandwidth: In an early implementation of the CIGALE network, excess traffic was dropped when no buffer was available. As expected, simulation showed that the network did not get blocked by overload [15]. However, delivered traffic was decreasing slowly with increasing offered load (Fig. 5). This loss of throughput was a direct consequence of dropping packets on their way across the network, since they consumed resources without contributing to delivered traffic.
The analysis of overload conditions revealed that packet drop did not occur until a particular node to node link was used at 90 percent of its capacity. Under such a load, and assuming stochastic traffic, queueing theory predicts an average queue size of about nine. The total number of buffers available in a node was 20. Thus, the probability of buffer shortage was high.
This observation led to the rationale that buffer shortage was not a cause but only a consequence of overload. There would never be buffer shortage if packets could be forwarded, that is, if there were enough bandwidth available. Furthermore, the more buffers used, the longer the transit delay.
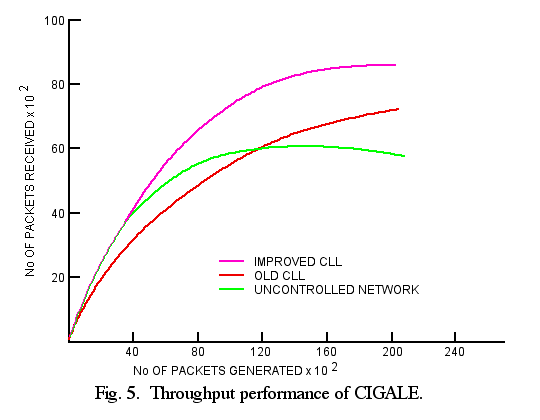
Therefore, buffers are a necessary evil to damp out transient traffic bursts; they need not be provided in excess of a required minimum. If one considers that transit delays in overload conditions should not exceed three times the minimum transit delay, then there should be no more than two or three packets waiting for transmission in front of every link. This average queue size corresponds to a 70 percent load. Other studies have reached similar conclusions.
The channel load limiter (CLL) scheme devised for CIGALE was described initially in [32]. It had two major objectives:
- throttle traffic in relation to link load, and
- exert selectivity in throttling sources contributing to overload.
Various simulations were performed to assess the validity of the CLL scheme and select a proper parameter tuning. An important result of the simulation was several improvements and simplifications to the initial design. A final report is given in [26].
The principles of the CLL workings are as follows. Every node to node link is monitored by the sending node. Under a certain load factor, set at 0.7, the link is deemed in normal state. Over this threshold. it is in warning state.
When a packet is routed to a destination Dj in warning state, a signaling packet, called a choke packet, is sent back to its source. Then, the source throttles traffic towards Dj. In case the source, which has received choke packets, does not reduce its traffic, a tripping mechanism in the input node drops packets sent to Dj.
The detailed algorithms tuned for CIGALE are given in a series of reports [27], while the description presented here is necessarily limited to basic principles. Simulation and implementation of the CLL scheme have shown that it is effective and robust, both under persistent and transient heavy overloads [14]. Throughput improvement compared to a network without congestion control is shown in Fig. 5.
One merit of a bandwidth based scheme, such as CLL is that it operates on the effective network load since it takes into account real packet lengths. Buffer based schemes usually assume full length packets, because most packet networks allocate maximum length buffers regardless of real packet length.
The selectivity of the CLL scheme consists in throttling primarily sources contributing the major proportion of traffic on overloaded links, while others are only slightly affected. This is a result of simulation work. However, it could be argued that a few high rate sources are no more responsible for congestion than scores of low rate sources. Who is causing congestion, in a jurisdictional sense, is an entirely different issue, which congestion control is not designed to handle.
b) Stream-wise: In the stream-wise approach, source-destination pairs are identified within the network in order to exert control on well defined data streams. Several technical variants have been implemented or analyzed. They fall into two broad categories: end-to-end and step-wise.
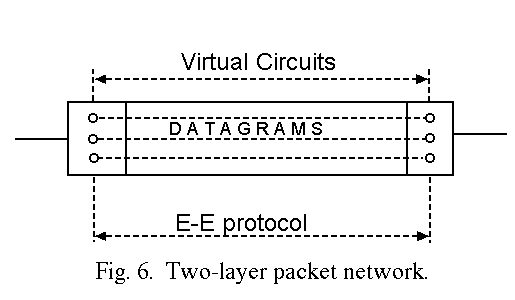
i) End-to-End (E-E): In the E-E approach the network is a two-layer structure (Fig. 6). The inner layer is a datagram network with or without congestion control mechanisms of its own. The outer layer contains additional functions including an E-E FC protocol applying on individual data streams often called virtual circuits (VC).
VC's may be permanent and fixed in number (e.g., ARPANET), or they may be set up and released on subscribers' requests (e.g., DATAPAC). The E-E protocol used to control data flow on VC's is strictly internal network machinery. It is not visible to network subscribers. However, some functions of the E-E VC protocol may be accessible for subscriber's convenience. For example, E-E acknowledgments and credits may be passed across the network subscriber boundary, in order to help E-E subscriber protocols (which bear no relationship with the network E-E protocol).
Network congestion control consists of: 1) limiting the number of VC's, and 2) limiting the number of packets in transit over a VC. In a sense, this is equivalent to limiting the total number of packets in transit, as in the isarithmic scheme. On the other hand, this E-E scheme is more constraining than the isarithmic one, as it sets two thresholds instead of one.
When the number of VC's is fixed, it is limited by construction. When VC's may be set up on request, there is no simple way to limit their total number, unless requests are centralized. Thus, implementers attempt to determine dynamically, within each source or destination node, a certain maximum threshold, which results both from the number of VC's terminating in the node, and the predicted traffic on each VC. Calls for new VC's are rejected when the threshold is reached, or some selectivity may be applied in handling calls. Occasionally, existing VC's may have to be destroyed.
Predicting the traffic on each VC is usually based on parameters provided by the caller when a VC is established. For example, the terminal speed, or the throughput class of X.25. Such predictions are expressed in terms of steady traffic. They may use maximum or average figures, but they do not represent transient traffic patterns.
When the number of packets in transit per VC is limited to a fixed threshold, VC's taking few hops are favored, as they can carry a higher packet rate than VC's taking a larger number of hops. This predictable effect has been confirmed by measurements on the ARPANET [20], [46]. It can be counteracted by increasing network connectivity, so that no route would require more than a few hops.
Whether such methods are valid is open to questions. In the case of the ARPANET, it has been recognized that limiting the number of packets in transit per VC leads to a reduction of the available network bandwidth, without eliminating the risk of local congestion [20]. Other networks, mainly common carriers, use dynamic thresholds, since they have to handle both permanent and switched VC's, but no report is available on actual traffic analysis or modeling. Very likely, the same kind of dilemma should arise: underutilized resources, or risks of congestion.
Fighting congestion by dropping VC calls entails some overhead. If the call is dropped at the originating node, the overhead is minimal; but when the decision is taken by the destination node, two packets (call and reject) are carried throughout the network to no avail. If the calling subscriber then repeating calls, self-triggered congestion could develop. Apparently, common carriers are aware of this possibility some of them charge subscribers for call packets rejected due to network congestion. It appears that some more elaborate mechanism would be more appropriate, e.g., informing originating nodes about congested destinations. Congestion at datagram level may compensate for loopholes at the VC level.
ii) Step-wise: Another typical technique used for implementing VC's is to build them as a concatenation of node to node logical channels, as shown in Fig. 7.
Each VC is flow controlled on each individual logical channel, either between subscriber and network, or between adjacent nodes. Inside a node, logical channels are stitched together through a packet (or character) queue. Examples of networks implementing this technique are TYMNET. TRANSPAC and the GMD net [37], [9], [13].
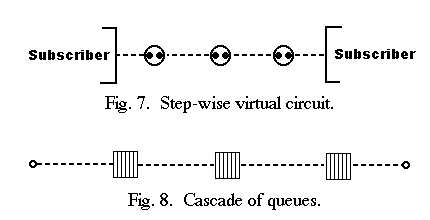
For each individual VC, the network may be modeled as a cascade of queues, as shown in Fig. 8. It is easy to understand that simple credit mechanisms per VC are sufficient to prevent congestion, assuming that every node knows precisely how many resources (buffer, processor, bandwidth) are available per VC.
Again, the FC problem is converted into a resource sharing problem, since every node must face a constantly changing demand for serving existing VC's and setting up new ones. When resources are depleted, some VC's may be dropped, but the most usual network reaction is an increase in transit delays, due to the slowing down of queue service. There should occur no deadlock, however, provided that every node has allocated, permanently, to every VC the minimum amount of storage necessary for accepting upstream traffic, once downstream saturation has disappeared.
Instead of allocating one buffer per VC in every node, the GMD network uses the buffer class method (BC) described earlier. This method prevents deadlock and reduces the minimum amount of node storage, but it carries some drawbacks already mentioned.
While congestion on established VC's may be avoided, the method leaves out two major problems: 1) sharing network resources among VC's, and 2) setting up new VC's.
As opposed to datagram based machinery, packets (or characters) are not automatically forwarded just because they happen to wait in an output queue. The selectivity made possible by step-wise VC machinery implies that a decision be made as to which one out of hundreds or thousands of VC queues is to be served next, and for how long. This is similar to task dispatching in a real-time system: the less predictable the traffic. the more overhead in sampling and context switching in order to service every traffic stream on a demand basis.
The storage space available to a node must be allocated to individual VC queues, either by anticipation, or on demand. In TYMNET, every VC is allocated a fixed length buffer [37], due to the fact that one end of a VC is normally a slow speed interactive terminal. As users are charged for connection time, they tend to keep their terminal busy, thus traffic is fairly predictable. A TRANSPAC early design called for fixed buffer reservation for every VC in every node. However in a general context where VC's terminate in computers, traffic is much less predictable, thus this tentative approach was abandoned in favor of dynamic allocation [42].
The other problem is to decide whether or not a new VC call can be accepted, and if so, how it is to be routed. Ideally, such a decision should take into account the existing and predictable network load, both of which are not obtainable conveniently. The choice made for TYMNET is to delegate the setting up of a new VC to a central network supervisor, which keeps track of the load put onto individual nodes and circuits, and constructs a route for a new VC. In case of overload, calls are rejected by the supervisor. Algorithms used are discussed elsewhere in this special issue. HYPERLINK
TRANSPAC has no central supervisor, and the decision to accept a new VC is taken individually by every solicited node, based on both local information and network-wide information provided by a control center. Algorithms published so far appear to be rather complex, and depend on a number of parameters intended for future tuning [42]. No simulation results or actual traffic statistics are available at this point. Thus, there is no way to evaluate the effectiveness of the mechanisms.
While the step-wise technique is clearly appropriate to throttle traffic selectively, it is not clear how it reacts to bursty traffic and how individual VC traffic interfere with one another. Network resources are allocated on the basis of educated guesswork which does not guarantee any throughput and transit delay. If it is easy to understand that persistent congestion cannot occur, overload conditions may very well cause excessive transit delays and corresponding throughput degradation. Analysis and evaluation of the step-wise approach at network level remain undocumented. There is so far no evidence that it is more efficient than a simple datagram based FC scheme.
Besides, the step-wise method entails operational constraints. A VC requires tables and pointers in every intermediate node, not just the origin and destination nodes. Thus, it is more vulnerable to network failures. Although network implementers claim that a VC could be reconstructed automatically on a different route without loss of data, this capability has not yet materialized in commercial networks. VC failures are thrown upon subscribers. Furthermore, the overhead in opening and closing VC's is a function of the number of traversed nodes. It is especially cumbersome in setting up internetwork calls.
c) Hybrid schemes: Further investigations into the FC problem tend to turn out composite methods, which endeavor, to take the best of known schemes without their less desirable features. One direction of research aims to let the packet network identify natural data streams without taxing subscribers with an awkward VC machinery. Basically, the packet network carries datagrams, but it assumes that most of them belong to data streams flowing between subscribers' equipment. Two schemes have been studied, one based on stream tables, the other on packet trails. They are briefly examined here.
Stream table: Every node builds a local table summing up a smoothed evaluation of the traffic per data stream [8]. A data stream is identified when a certain number of packets carry the same source-destination pair. Since the stream table has a limited size, only the most frequently observed streams are put under control. When a node output link load reaches the congestion threshold (e.g., 70 percent) the stream table is scanned, and choke packets are sent to every source that contributes to the link load. Sources are supposed to follow some regulation pattern in slowing down and speeding up traffic. As a whole this scheme is a refinement of the CLL scheme presented earlier.
Packet trail: The first packet of a stream acquires, in every traversed node, a temporary buffer reservation and leaves an imprint [10], i.e., a table entry containing the same sort of information as a VC entry in a step-wise implementation. In other words, when the packet reaches its destination a VC has been constructed inside the network. Subsequent packets are directed over the same route, and may be throttled by a step-wise FC scheme. If a routing change occurs, or if a time expires, the trail disappears and a new one is opened by the next coming packet. Additionally, two trails may merge into a single one, thereby reducing overhead in heavy traffic areas.
Both schemes have been simulated, and have produced acceptable performance figures. On the other hand, there remains further ground to investigate because more complexity brings along more parameters, and it would be premature to draw conclusions based only on a small set of simulation runs.
d) Congestion control and routing: Using routing decisions as a tool to spread traffic and optimize the use of network resources has long been a temptation for network designers. However, so far, no successful scheme has ever been worked out. A few basic observations may emphasize some intrinsic difficulties:
- to the extent that the initial route selected for a packet was the best one, any other route is likely to consume more network resources;
- if congestion is due to a persistent cause, diverting traffic onto more routes only delays the cure and is likely to spread more congestion;
- if congestion is due to a transient cause, it may have disappeared by the time routing changes occur; and
- when VC's are built into a packet network, the constraint of sequential delivery is conflicting with rapidly changing routes, because more packets would reach their destination node out of order.
Flow allocation algorithms, such as used in transportation networks, assume steady flows and fixed network topology. It is conceivable that a thorough knowledge of predictable traffic patterns could allow a precalculation of optimized routes for individual flows. Various tariff gimmicks may help in turning stochastic flows into steady ones. Bandwidth shortage may also be a factor forcing subscribers to batch their traffic. Therefore, the idea of using routing as a resource sharing tool should not be discarded altogether. However, its application is likely to remain limited to some specific networks, or to some well identified traffic flows. In that case predetermined routes or permanent step-wise VC's may be a satisfactory solution.
Dynamic routing (i.e., in real time) coupled with congestion control stumbles against the problem of carrying out a network-wide performance improvement based only on locally available information. Even if every node acquires some knowledge of the whole network state, delays inherent to propagation and consistency checking work against real time operability. Thus, this area remains open to more research [3], [12], [39].
e) Congestion control and topology: Resource sharing implies resource pooling. A specific geographical distribution of network resources puts definite constraints on resource sharing, because it sets limits on local resource pools made available to each node. Therefore, topology must be included as one of the factors bearing on network optimization. Historically, node to node links were leased circuits which could require weeks or months to be installed. The advent of switched digital systems and high bandwidth channels allows a new approach in which nodes would dial out high speed circuits towards final destination nodes for transmitting perhaps only a few packets. Packet routing would become a matter of dynamically adaptive topology.
Present day packet networks are primarily designed to share fixed bandwidth circuits, and bandwidth shortage is an essential factor of network congestion. With dial out capabilities, most bandwidth limitations would be removed, and other congestion factors could take precedence, e.g., storage access time, processor switching, bus speed. New parameters would have to be dealt with: dial-up time, circuit holding time, call charge. limitations in dial out facilities, or a mix of fixed and adaptive topology may require new routing strategies, in order to minimize network operation costs.
f) Review of congestion control methods in S-F networks: As exemplified by the descriptions given earlier, basic congestion control schemes are in limited number, but there is no limit for the variants combining several schemes or introducing a score of adjustable parameters.
Existing networks do not appear to suffer from congestion in the sense that no persistent blocking occurs. However, some common carrier networks experience obvious traffic problems at times when VC set up or output standstill last ten seconds or more. Broken VC's are another visible effect which does not necessarily arise from congestion. However, no firm conclusions can be drawn without detailed study of internal network statistics and logs, which carriers do not make available.
Analysis and simulations of global network behavior have been performed initially on datagram networks, and in several cases validated by implementations. While network optimization remains an open question, for any kind of packet network, it has been established that datagram traffic can be kept under control with simple mechanisms, which apply selective backpressure onto specific sources. However, simulations or implementations have been limited to single level networks composed of a few dozens of nodes. Interconnected or hierarchical network structures have received little attention [7].
Larger networks use VC's, as their designers believed that FC would be more manageable than in datagram networks. On the other hand VC networks analysis and simulations have lagged, presumably due to the sheer complexity of the problem. Beside the VC management overhead is imposed on the subscriber, it is gradually perceived that large networks will have to carry diverse classes of traffic for which VC mechanisms are unfit. File transfer or facsimile would be better handled with fixed bandwidth switched circuits, distributed database management, and message transfer call for datagram service. Thus, other FC schemes will be necessary for the overall management of network resources.
Criteria for selective throttling remain somewhat arbitrary, and are often chosen for ease of implementation. It has been suggested that traffic flows should be selected in order to maximize the carrier's revenues [29]. Such a policy would be similar to bumping lower fare passengers when a plane has been overbooked.
2) Memoryless networks: Actually, the generic qualifier memoryless applies to networks using shared transmission media which have no storage capability for queueing traffic. Due to propagation delays, amplifiers and shift registers, there may be some limited amount of data in transit, but this is more a technical constraint than a storage function. Local networks structured as rings or trees, broadcast radio or satellite networks fall within this category [4], [18], [16].
Transmission channels used to forward packets are shared by competing processes, which attempt to acquire a time slot whenever they want to transmit a packet. A very large number of schemes have been investigated by analysis or simulation, and a discussion of their characteristics is out of the scope of this paper. Here, we shall focus only on the basics of congestion.
Since memoryless networks have no storage, buffer shortage cannot occur. Nevertheless, congestion may develop in the sense that, past a certain threshold in offered traffic, the network's useful throughput may decrease and eventually drop to nil. A milder form of congestion is observed if the whole network capacity is monopolized by a subset of correspondents, while others are indefinitely shut off. These two forms of congestion derive from the channel allocation policy.
Two major principles are used for allocating a transmission channel: either a turn is passed around, or it is acquired by contention among candidate senders. In the first case, the turn may never be given to some sources if the circulation algorithm is not fair. In the second case, contention consumes a certain amount of bandwidth; and in heavily loaded conditions, the remaining useful bandwidth may be a vanishing part.
When channel allocation is controlled by a turn, the logical problem of ensuring fairness is similar to process scheduling In a multiprogramming system. Fairness is a subjective concept which should be defined in terms of service policy (FIFO, equal share, weighted share, priorities, etc.). Implementing fairness should not be a problem. However, local networks designs tend to put a strong bias towards low implementation costs. Saving a few components on a circuit board is often a clear advantage. Thus, the turn may be passed around in some simplistic way, e.g., last receiver, next on the ring, fixed sequence. A priori, all these schemes are acceptable, at least under appropriate traffic assumptions. But can we be sure that some unanticipated traffic pattern will be handled satisfactorily? Thus, the need to validate the network design, or to put additional safeguards in the implementation.
Problems associated with contention fill a broader spectrum, due to the large number of design options. By construction, every potential source has a permanent turn. When a resource transmits, it may collide with one or more others, and the result is garbled transmission. Thus, colliding sources must attempt a new transmission. The overhead is lost bandwidth and delay.
A review of existing and proposed methods for handling collisions and retransmissions is out of the scope of this paper. In general, designers attempt to tackle the congestion problem in two distinct steps: 1) minimize bandwidth loss due to a collision, and 2) minimize the probability of collision on retransmissions. At this point, it must be established by analysis or simulation that the network throughput remains stable when it is overloaded. This condition can be met provided that sources apply algorithms of self restraint, such as not transmitting when some other transmission is already in progress, or adjusting their retransmission delay in relation to the channel load [44].
In any case, there appears to be, almost always, a certain maximum threshold for the number of new packet arrivals, because each one introduces a certain collision probability. Even if collision overhead is minimized, accumulated collisions will eventually eat up useful traffic.
If the channel bandwidth is large enough, the congestion threshold may be practically unreachable, due to built-in limitations in the number of sources and their maximum throughput. Otherwise, hybrid schemes may be used. In brief, they combine contention and turn. A certain fraction of the bandwidth (i.e., some time slots) is allocated by contention, and carries reservation signals allocating the remaining time slots. Thus, collision overhead may never exceed a predetermined ratio.
To sum up, congestion control in memoryless networks appears to be simpler and better understood than in S-F networks. Channel loads higher than 0.98 may be obtained in local networks with rather simple mechanisms which sense collisions immediately [41]. Satellite broadcast systems [16] require more sophisticated hybrid schemes because collisions can only be sensed after packets have been bounced back to earth. Broadcast radio systems [18] allow less flexibility, because transmitting equipment blinds its own receiver, and prevents collision detection at the sender's site. Nevertheless, the number of design options is always large enough to prevent congestion in practical operating conditions.
IV. SERVICE DEFINITION
A. Resource Sharing Principles
A subsystem, such as a packet network or a broadcast channel, is shared by a number of traffic streams. As we have seen earlier, E-E protocols between correspondents may be logically independent from underlying communication subsystems, but their efficiency may be directly affected by the service characteristics. Thus, the problem is that of maintaining stable characteristics under adverse conditions.
The same problem exists in any resource sharing system, e.g., multiuser operating systems. There exists no magic recipe when demand exceeds supply. Either service degradation occurs or some users are denied service, or both. An implication is that a communication subsystem will not provide stable service unless
- resources exceed the maximum required, or
- there are classes of service given preference over others.
Except during some transient conditions, existing networks offer a rather stable transit delay up to a certain load factor, which depends on each network's characteristics .
Maintaining load below that threshold is a way to offer guaranteed and minimum delay. It is also a way to guarantee a certain fraction of unused resources.
Maximum service quality and maximum resources utilization are conflicting objectives. Rather than trying to solve an impossible dilemma, it would be more appropriate to introduce several classes of services whose characteristics can be achieved independently without conflicting with objectives of resource utilization [19]. As an example, there could be three classes of service:
- minimum transit delay,
- guaranteed throughput, and
- guaranteed delivery.
Minimum transit delay is the natural mode of operation of a well designed network that is not overloaded. In addition, delay variations are minor, except in occasional cases of network failures and routing changes. Thus, delay could be guaranteed to be lower than a nominal figure for 99 percent of the packets. In addition, an optional packet lifetime mechanism could guarantee that no packet would be delivered beyond a maximum transit delay, say, five times the nominal delay. Indeed, E-E protocol efficiency is better achieved with stable delays and some rare packet losses than by integrity and varying delays.
Guaranteed throughput is made up of guaranteed acceptance, and, practically, it implies also a certain form of guaranteed transit delay. Indeed, large variations in delay would introduce instantaneous rate variations, presumably not satisfactory for an efficient operation of sender/receiver devices. But guaranteed delay does not mean minimum delay. In other words, additional queueing time could be acceptable. This can be accommodated in parallel with minimum delay traffic, as long as the two kinds are distinguished by a priority lag, and the network resources exceed the total requirements of both traffics.
Then, a third class of service may be defined, in order to take advantage of the excess of resources statistically unused. since traffic of this category shall give way to others it cannot be guaranteed for delay, nor for throughput. But it could be guaranteed for delivery. In other words, intermediate additional storage could be provided, so as to be ready to !ill up any available line capacity, and an E-E protocol would guarantee traffic integrity. This kind of hitchhiking traffic could be offered at a discount rate.
In conclusion, it has to be restated that a guarantee for service characteristics requires some excess capacity. Therefore, it requires a prior knowledge of the maximum acceptable traffic in each class.
CONCLUSIONS
As we have pointed out, FC is basically a resource sharing and optimization exercise. E-E FC is moderately difficult, as It involves a limited variety of resources at either end of a data stream. Congestion control in an S-F packet network is still an active research area. The number of parameters involved in a realistic situation, and the possibly transient nature of the phenomenon, are major obstacles to a comprehensive theoretical understanding. Practical solutions rely more on intuitive recipes than on systematic engineering.
The fact that recipes may work satisfactorily only reflects a frequent situation, that is that practice precedes theory. Simple recipes are more interesting than intricate ones, not only because their implementation is more economic, but mostly because they bring more insight into fundamental principles.
FC in data networks is still an area where considerable investigation remains to be done. Techniques used so far are borrowed from the bag of tricks developed for centralized systems. However, distributed systems bring about new problems due to propagation time and unreliability associated with any form of long distance communication.
A few principles of distributed systems operation are now emerging. They could be summarized as follows.
- Consistency has a price, in delay or in bandwidth. On the other hand, inconsistency leads to unpredictable states.
- Algorithms to maintain consistency may be centralized or distributed. In both cases, redundancy is necessary to ensure error recovery.
- Error recovery algorithms are in charge of eliminating inconsistency. However, they may not succeed.
In line with these principles, congestion control recipes being investigated take into account more global variables, which have to be acquired from the whole network. In order to avoid instability, all nodes must acquire mutually consistent states. This cannot be ascertained continuously, because updates are necessary. Thus, a practical approach would be a discrete succession of consistent states separated by blind states during which a new global state is phased in. Such problems are at the core of future research into distributed systems.
REFERENCES
[1] V. Ahuja, "Routing and flow control in systems network architecture," IBM Systems Journal, vol. 18, no. 2, pp. 298-314, 1979.
[2] C. J. Bennett, "Supporting transnet bulk data transfer," in Proc. Int. Symposium Flow Contr. Computer Networks, Versailles, France. Feb. 1979, pp. 383-404.
[3] W. Chou, J. D. Powell, and A. W. Bragg, "Comparative evaluation of deterministic and adaptive routing," in Proc. Int. Symposium Flow Contr. Computer Networks, Versailles, France, Feb. 1979, pp. 257-285.
[4] D. Clark, K. T. Pogran, and D. P. Reed, "An introduction to local area networks," Proc. IEEE, Vol. 66 No 11, pp. 1497-1517, Nov 1978
[5] A. Danthine and E. Eschenauer. "Influence on the node behaviour of the node-to-node protocol," in Proc. ACM-IEEE 4th Data Communications Symposium, P.Q., Canada, Oct. 1975, pp. 7.1-7.8.
[6] D. W. Davies, "The control of congestion in packet switched computer networks," IEEE Trans. Communications, pp. 546-550, June 1972.
[7] D. W. Davies, "Flow control and congestion control," in Proc. COMNET 77, Budapest, Hungary, John Von Neumann Society ed., Oct. 1977, pp. 17-38.
[8] M. Davidian and M. Mahieu, "Controle de congestion des reseaux de datagrammes: simulation," in Proc. Int. Symposium Flow Contr. Computer Networks, Versailles, France. Feb. 1979, pp. 189-199.
[9] J R. Despres, A. Danet. B. Jamet, G. Pichon, and P. Y. Schwanz, "Packet switching in a public data transmission service: The TRANSPAC network," in Proc. EUROCOMP (European Computing Conference on Communications Networks), London, Sept. 1975. pp. 331-347.
[10] M. Elie, "Traffic control by latency in a packet switching." in Proc. Int. Symposium Flow Contr. Computer Networks, Versailles. France, Feb. 1979. pp. 201-210.
[11] M. Gerla and l. Kleinrock, "Flow control: A comparative survey," IEEE Trans. Communications pp. 553-574, Apr. 1980.
[12] M. Gerla, and P. O. Nilsson, "Routing and flow control interplay in computer networks," in Conf. Record ICCC 80, Oct. 1980, pp. 84-89.
[13] A. Giessler, J. D. Haenle, A. Koenig, and E. Pade, "Free buffer allocation—An investigation by simulation," Computer Networks, vol. 2, pp. 191-208, July 1978.
[14] J. L. Grange, and J. C. Majithia, "Congestion control for a packet-switched network," Computer Communications pp. 106-116, June 1980.
[15] M. Irland, "Simulation of CIGALE 1974," in Proc. ACM-IEEE 4th Data Communications Symposium, P.Q., Canada, Oct. 1975, pp. 5.13-5.19.
[16] J. M. Jacobs, R. Binder, and E. V. Hoverstein, "General purpose packet satellite networks," Proc. IEEE, pp. 1448-1467, Nov. 1978.
[17] R. E. Kahn and W. R. Crowther, "F1ow control in a resource sharing computer network," IEEE Trans. Communications, pp. 539-546, June 1972.
[18] R. E. Kahn, S. A. Gronemeyer, J. Burchfiel. and R. C. Kunzelman, "Advances in packet radio technology." Proc. IEEE, pp. 1468-1496, Nov. 1978.
[19] F. Kamoun, A. Belguith. and J. L. Grange, "Congestion control with a buffer management strategy based on traffic priorities." in Conf Record, ICCC 80. Oct. 1980. pp. 845-850.
[20] L. Kleinrock and H. Opderbeck, "Throughput in the ARPANET: Protocols and measurements," in Proc. ACM-IEEE 4th Data Communications Symposium, Quebec City., P.Q., Canada. Oct. 1975. pp. 6.1-6.11. Reprinted in IEEE Trans. Communications, Vol COM-25 No 1, pp 95-104, Jan 1977.
[21] L. Kleinrock and P. Kennani, "Static flow control in store-and-forward computer networks." IEEE Trans. Communications, pp. 271-279, Feb. 1980.
[22] L. Kleinrock and C. W. Tseng, "Flow control based on limiting permit generation rates," in Conf. Record ICCC 80, Oct. 1980. pp. 785-790.
[23] S. S. Lam and M. Reiser, "Congestion control of store-and-forward networks by input buffer limits," in Conf. Record National Telecommunication Conference Dec. 1977, pp. 12:1.1-12:1.6.
[24] S. S. Lam and Y. L. Lien, "An experimental study of the congestion control of packet communication networks." in Conference Record, ICCC 80. Oct. 1980. pp. 791-796.
[25] G. Le Lann and H. Le Goff, "Advances in performance evaluation of communications protocols." in Conf Record ICCC 80, Toronto, Ont., Canada. Aug. 1916. pp. 361-366.
[26] J. C. Majithia, M. Irland, J. L. Grange, N. Cohen, and C. O'Donnell, "Experiments in congestion control techniques," in Proc. Int. Symposium Flow Contr. Computer Networks, Versailles. France, Feb. 1979, pp. 211-234.
[27] J. C. Majithia, C. O'Donnell, and J. L. Grange, "Performance investigation of congestion control mechanisms in the CIGALE network," Univ. of Waterloo Research Inst.. Dec. 1979. Paper 811-08, 40 pp.
[28] J. M. McQuillan, "Interactions between routing and congestion control in computer networks," in Proc. Int. Symposium Flow Contr. Computer Networks. Versailles, France, Feb. 1979, pp. 63-75.
[29] D. Nesset, "A protocol for buffer space negotiation," in Proc. 4th Berkeley Workshop on Distributed Data Management & Computer Networks, p. 22. 284-305, Aug. 28-30 1979.
[30] L. Pouzin, "CIGALE, the packet switching machine of the CYCLADES computer network," in Proc. IFIP Congress. Aug. 1974, pp. 155-159.
[31] —, "Virtual circuits vs. datagrams: Technical and political problems," in Conf. Record, AFIPS-NCC, June 1976, pp. 483-494.
[32] —, "Distributed congestion control in a packet network: The channel load limiter," in Proc. 6th Congress Gesellschaft fur Informatik, Stuttgart, Germany, Sept. 1976. pp. 16-21.
[33] W. L. Price, "Simulation studies of an isarithmically controlled store and forward data communication network," in Proc. IFIP Congress, Aug. 1974. pp. 151-154.
[34] W. L. Price and J. D. Haenle, "Some comments on simulated datagram store-and-forward networks." Computer Networks. vol. 2, pp. 70-73, Feb. 1978.
[35] W. L. Price, "A review of the flow control aspects of the network simulation studies at the National Physical Laboratory," in Proc. Int. Symposium Flow Contr. Computer Networks, Versailles. France. Feb. 1979. pp. 17-32.
[36] E. Raubold and J. Haenle, "A method of deadlock-free resource allocation and flow control in packet networks," in Conference Record, ICCC 76. Aug. 1976. pp. 483-487.
[37] J. Rinde and A. Caisse, "Passive flow control techniques for distributed networks," in Proc. Int. Symposium Flow Control Computer Networks. Versailles, France. Feb. 1979, pp. 155-160.
[38] H. Rudin, "Chairman's remarks: An introduction to flow control." in ICCC 76 Conf. Record Aug. 1976, pp. 463-466.
[39] H. Rudin and H. Mueller. "On routing and flow control." in Proc. Int. Symposium Flow Control Computer Networks. Versailles. France, Feb. 1979, pp. 241-255.
[40] M. Schwanz and S. Saad. "Analysis of congestion control techniques in computer communication networks," in Proc. Int. Symposium Flow Contr. Computer Networks. Versailles. France. Feb. 1979. pp. 113-130.
[41] J. Shoch and J. A. Hupp. "Measured performance of an ETHERNET local network," XEROX PARCo p. 22. Feb. 1980.
[42] J. M. Simon and A. Danet. "Controle des ressources et principe du routage dans le reseau TRANSPAC." in Proc. Int. Symposium Flow Control Computer Networks. Versailles. France. Feb. 1979. pp. 63-75.
[43] C. Sunshine. "Efficiency of interprocess communication protocols for computer networks." IEEE Trans. Communications, pp. pp. 287-293, Feb. 1977.
[44] F. A. Tobagi. M. Gerla, R. W. Peebles, and E. G. Manning. "Modeling and measurement techniques in packet communication networks," Proc. IEEE, pp. 1423-1447, Nov. 1978.
[45] J. W. Wong, "Flow control in message-switched communications networks." Computer Communications, pp. 67-74, Apr. 1978.
[46] D. Wood, "Measurement of user traffic characteristics on ARPANET," in Proc. ACM-IEEE 4th Data Communications Symposium P.Q. Canada. Oct. 1975. p. 9.2.
[47] H. Zimmennann, "The CYCLADES end-to-end protocol," in Proc. ACM-IEEE 4th Data Communications Symposium Oct. 1975. pp 7.21-7.26.
*

Louis Pouzin is an engineer from Ecole Polytechnique in France.
He joined the computing field in 1957. after a few years with a telephone company. Since then he has worked for a computer manufacturer, a software house, a car manufacturer, and a research institute in computing. His background includes the development of large software systems. He directed the CYCLADES project. an experimental computer network in France. In 1980. he joined the research center of the French Telecommunications Administration to develop pilot projects. He teaches at a Paris university.
Mr. Pouzin is the former Chairman of IFIP-TC.6. the technical committee on data communications. and author of over 50 publications.